

New Technologies
Transformer vs. DeepL: New Attention Based Approaches to Machine Translation
Machines can now pick up nuanced information and translate sentences more naturally.
Machines can now pick up nuanced information and translate sentences more naturally.
Back in December of 2016, the New York Times published an article on the Google Brain team and how neural networks have elevated the accuracy of Google Translate to a human-like level. Still, these systems based on complex architectures involving recurrent neural networks (RNN) and convolutional neural networks (CNN) were computationally expensive and were limited by their sequential nature.
To illustrate, take the following sentences where the word “bank” has a different meaning in context:
“I arrived at the bank after crossing the road.”
“I arrived at the bank after crossing the river.”
Humans can quickly determine that the meaning of “bank” depends on “road” or “river.” Machines using RNNs, however, process the sentence sequentially, reading every word by word, before establishing a relationship between “bank” and “road” or “river.”
This becomes a bottleneck for the computer running on TPUs and GPUs that utilize parallel computing. Although CNNs are less sequential than RNNs, computational steps to establish the meaningful relationships grow with increasing distance. Thus, both systems struggle with sentences like those presented above.
Both Transformer and DeepL overcome this limitation by applying an attention mechanism to model relationships between words in a sentence more efficiently. While the actual implementation of each of the systems is different, the underlying principle spans from the paper, “Attention Is All You Need.”
For a given word, attention-based systems quickly compute an “attention score” to model the influence each word has on another. The key difference is that attention-based systems only perform a small number of these computations and feeds the weighted average of the scores to generate a representation of the word in question.
This mechanism is applied to translation in the following way. Previous approaches to machine translation had a decoder create a representation of each word (unfilled circles below) and using the decoder to generate the translated result using that information. Attention-based systems add on the attention scores to the initial representations (filled circles below) in parallel to all the words with the decoder acting similarly.

Attention scores also allow the machine to visualize the relationship between the words. Take another coreference resolution example:
“The animal didn’t cross the street because it was too tired.”
“The animal didn’t cross the street because it was too wide.”
When translating this sentence to other languages where “it” can hold gender forms depending on its reference to “animal” or “street,” encoding the sentence with the correct relationship is vital. Attention scores can generate a visualization embedding this information in the following manner:
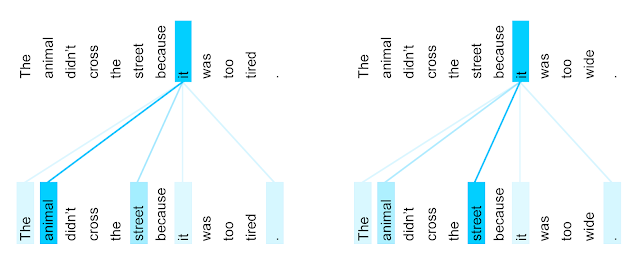
In the first sentence, the system picked up that “it” refers to the animal, whereas in the second, “it” refers to the street.
The implication of attention-based systems in the machine translation world is huge. The machine can now pick up nuanced information and translate sentences more naturally. From DeepL’s own blind testing, attention-based systems outperformed existing translators with fewer tense, intent, and reference errors:

You can try out Transformer using the tensor2tensor library from Google and the DeepL translator online via their website.
Join companies like Cox Communications, Yamaha, and Google who have selected Leverege to launch innovative IoT-enabled asset management applications to optimize operations, increase revenue, and delight customers.

Thanks for submitting your information. Our team will be in touch soon.

Skip the complexity of IoT and get highly configurable IoT applications tailored to your business.








.svg)

